
Håfa ådai! In our last post, we introduced our (still very much in beta!) AI-powered language translator tailored to serve Pacific Islander languages, starting with Samoan. As part of the Pacific Broadband and Digital Equity mission, our eyes are set on leveling the playing field and enriching digital interactions for communities across the Pacific region. With that in mind, we have now expanded our translator to include support for the Chamorro language, and we are working on changes to the translator that will allow us to add additional languages to the region.
Today’s post has a twofold focus. First, we’ll discuss the work we’ve done to assemble the translator’s components, avoiding technical jargon but providing enough detail to understand the project’s direction. Second, we’ll emphasize the opportunities we see for expanding the Translator to handle additional Pacific languages with better accuracy and utility. Such an approach could not only make AI more useful in these communities but also offer an avenue to protect and perpetuate the languages themselves.
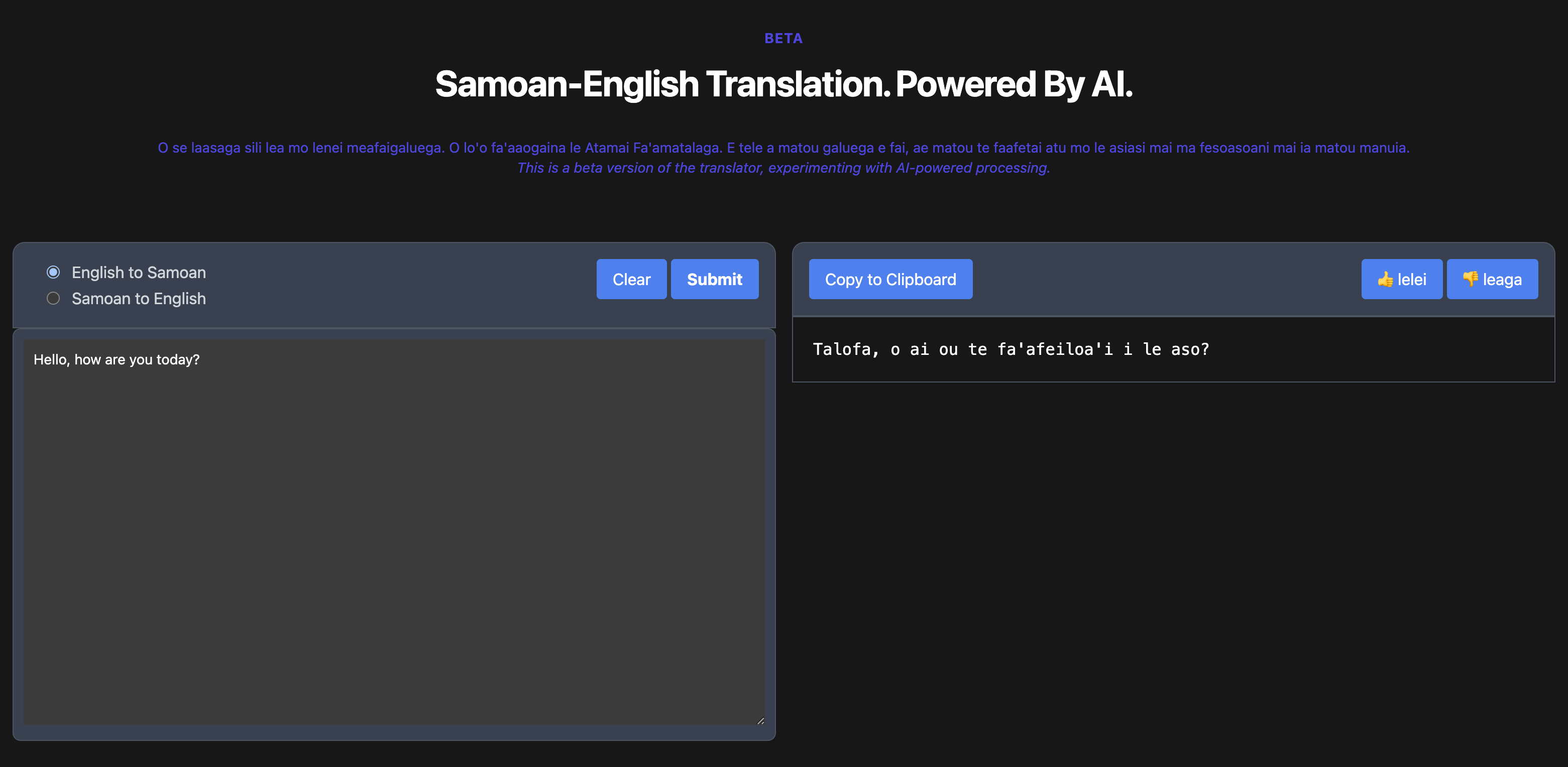
How the AI Translator App Works Today:
Our project is in the initial phase, focused primarily on data collection. However, the architecture is already designed for scalability and adaptability. Here’s how it works at this point:
Technology Stack:
Our application is built on a NextJS/React framework and is hosted on the Vercel platform. While Vercel offers a region in Northern California, this is geographically distant from some of our target islands—a challenge we are cognizant of and intend to address.
AI Model APIs:
The app acts as a centralized interface that pulls together multiple AI models—currently OpenAI’s GPT-3.5 and GPT-4, and Meta’s LLama 2. We are also looking to integrate Anthropic’s Claude in the near future.
Translation Process:
When a user submits a text for translation, the app sends this request to the selected AI model via its API. Prompt engineering techniques are used to improve the translation’s quality and speed, a process that will be refined over time.
Fine-Tuning and Updates:
We’re at the initial stage of working with AI models for fine-tuning. As the AI landscape is rapidly evolving, we plan to continuously update and plug in newly tuned models into our interface.
User Feedback:
A key feature of our app is the ability for users to submit feedback on translations. This feedback will be invaluable for model tuning and for enhancing the overall quality of the translation service.
The goal is not just to create a translation service but to establish a dynamic, evolving platform that adapts to the rapidly changing capabilities of AI and the specific needs of Pacific Islander communities.
Evaluation and Results: A Snapshot
The performance of our AI-powered translator is currently a mixed bag. While it can sometimes deliver impressively accurate translations, it also has moments of struggle. We’ve adopted a systematic approach to evaluate the efficacy of different models:

Scoring System:
1 point for a direct match 0.5 points for a close match 0 points for no match or no response
Samoan to English Translations:
GPT-4 scored an impressive 12 out of 14 points on simple conversational phrases. GPT-3.5, the best free model from OpenAI, garnered 7.5 points. Meta’s LLama 2 trailed behind at 5.5 points.
Chamorro Translations:
GPT-4 scored 14.5 out of 21 on a basic vocabulary test, showing promise despite some limitations. GPT-3.5 actually edged out slightly, scoring 15 points on the same test. LLama 2 also did surprisingly well with a score of 14.5 but proved expensive to run and slow in execution.
One of the most intriguing challenges we face is defining what “success” really means in the context of language translation. Given the enormous linguistic diversity of Pacific languages—which have developed under very different circumstances from English and from each other—a deterministic 1-to-1 translation is often not feasible.
We do have some challenges moving forward. First, we are at the outset of the project and have much ground to cover in terms of testing and fine-tuning our models for optimal performance. Rigorous, ongoing evaluation will be paramount. Second, the invaluable role of user feedback can’t be overstated. Input from the community will not only help us refine our translator but also shape our evaluation metrics. While our current scoring system provides a baseline for assessing the capabilities of the AI models, it is by no means a definitive measure of their potential. In essence, we view these early metrics as a jumping-off point, a way to begin gauging our progress while also identifying areas in need of attention.
Assessing AIs beyond Translation
Scoring systems provide a tangible way to assess translation accuracy, but they’re just one piece of a much larger puzzle. Cultural and contextual nuances often go beyond what numbers can capture, and these elements are essential when considering how AI can genuinely benefit specific communities. Further exploration could delve into AI’s role in education—both in language preservation and as a learning aid for younger people. We’re also looking into practical applications like document translation in administrative or public health sectors. Essentially, our aim isn’t solely to perfect the algorithm but to explore how this technology can pragmatically support communities.
Beyond simple evaluation of AI models, we see the Translator as a possibly useful tool with potential for growth. While the primary function is language translation, we can envision ways to extend its utility to various applications, such as facilitating localized education, business, and governmental communication. With ongoing model fine-tuning and language additions, we hope the translator will help make inroads in reducing language barriers.
Ways We Can Improve and Expand the AI Translator
While our AI translator has made promising strides, we recognize there are several avenues for improvement and expansion. A “bolt-on” approach allows us to augment large commercial AI systems to better serve Pacific languages such as Samoan, Chamorro, and (recently requested) Carolinian, among others. Here are some targeted strategies we’re considering:
Lexicon Expansion:
We aim to build a tool that takes input text and expands lexicon coverage by identifying and adding translations for unknown words. This will teach new vocabulary to the commercial models and enhance their capabilities.
Text Normalization:
To make the input more accessible for commercial AIs, we’re developing pronunciation and text normalization tools. It is our hope to work with local teams in the various regions (or here in Hawai‘i) to help generate these, and this can form a major project with many useful technical outputs beside the AI. These will convert texts into a reader-friendly format, handling unique orthographies that are common in Pacific languages.
Grammatical Error Identification:
Recognizing that commercial models are prone to certain mistakes when translating Pacific languages, we’re in the early stages of creating a tool that will identify these errors and suggest corrections before sending queries. Again, user feedback will be critical for this work.
Ensemble Approach:
We plan to employ multiple commercial APIs on the same input and use a secondary model to rescore or select the best output. This ensemble approach helps leverage the strengths of each model, making for a more accurate translation.
Conversational Agents:
Another direction we’re exploring is the development of a conversational agent tool optimized for Pacific language domains. This agent would help frame queries and interpret responses, making the interaction more seamless for users.
Resource Expansion:
To directly improve model performance, we’re focused on expanding language resources such as aligned bitext, conversational data, and audio recordings. These resources will be used to retrain the commercial models over time.
Spoken Language Support:
One of our more challenging goals is to integrate support for spoken language. Given that many Pacific languages are primarily oral traditions, the value of a text-based translator is inherently limited. By incorporating voice recognition and speech-to-text technologies, we can make our tool more accessible and useful in real-world settings. This not only aids in real-time communication but also serves the critical function of preserving these languages in their most natural form—verbal communication. The integration of spoken language support would represent a significant leap forward. It acknowledges that true language support goes beyond the written word, embracing the oral traditions that are at the core of these languages. This is an ambitious but achievable goal.
The key to success lies in identifying the gaps in commercial models and filling them with complementary components. By doing so, we can leverage the power of large pretrained models while tailoring the technology to better serve Pacific communities.
In Our Next Post…
In this overview, we hope to have provided a comprehensive look at our AI Translator, detailing its current functionalities, our methods of evaluation, and the potential avenues for future expansion. Though still in its nascent stages and largely a one-person endeavor, the project shows promise for significant growth. We’ve laid out a roadmap that seeks not just to fine-tune algorithms but to develop a suite of tools designed to serve the unique needs of Pacific communities. As we move forward, we invite you to stay tuned for our next post, where we’ll discuss strategies for securing the resources, alignment, and community support needed to realize our ambitious goals.